Seminar 4: CNN Architecture
이번 포스트는 포항공대 비전랩, 곽수하 교수님의 CSED539: Computer Vision 과목의 슬라이드를 활용했음을 미리 밝힙니다 🙏
키워드
- AlexNet
- VGG
- ResNet
- pytorch implementation (→ seminar5)
시작하기 전에 Q&A 타임 ⏰
“지금까지의 내용은 별로 어렵지 않았죠? 만약 어려웠다면 여러분들이 공부를 안 해서 어려운 겁니다”
이번 포스트에서는 CNN Architecture에 대해 다룬다. 지금까지 많은 CNN Arhitecture가 제시되었지만, 우리는 AlexNet, VGG, ResNet 3가지 모델을 살펴보도록 하겠다. CNN Architecture는 Computer Vision 모델의 기반이 되기 때문에 알아두는 것이 논문 읽을 때 많은 도움이 된다. 📖

컴퓨터 비전에서는 “ImageNet“이라는 데이터셋이 있다. Image Classification를 위한 데이터셋을 HW3에서 활용한 “CIFAR10“보다 발전된 데이터셋이라고 보면 된다. ImageNet 데이터셋을 활용한 Image Classification 대회를 ILSVRC라고 하는데, 대회 이름은 별로 중요하지 않고 이 대회에서 우승을 차지한 모델들에 주목해야 한다. 모델을 보면 12년도의 AlexNet, 14년도의 VGGNet, 15년도의 ResNet이 우리가 오늘 살펴볼 모델들이다.
우승 모델의 경향을 살펴보면, 모델의 깊이(depth)를 높여 top-5 error rate는 줄어 왔다는 걸 볼 수 있다: 8 → 19 → 152. 특히 ResNet에서 깊이가 아주 크게 증가하고 error rate도 절반 가량 줄였다는 점에서 ResNet은 컴퓨터 비전 분야에서 이정표(milestone)라고 할 수 있다.
이제, AlexNet, VGG, ResNet 순서대로 CNN Architecture를 살펴보자. 각 모델에서 어떤 테크닉을 사용해 문제를 해결하고 모델을 보완했는지에 주목하자.
AlexNet
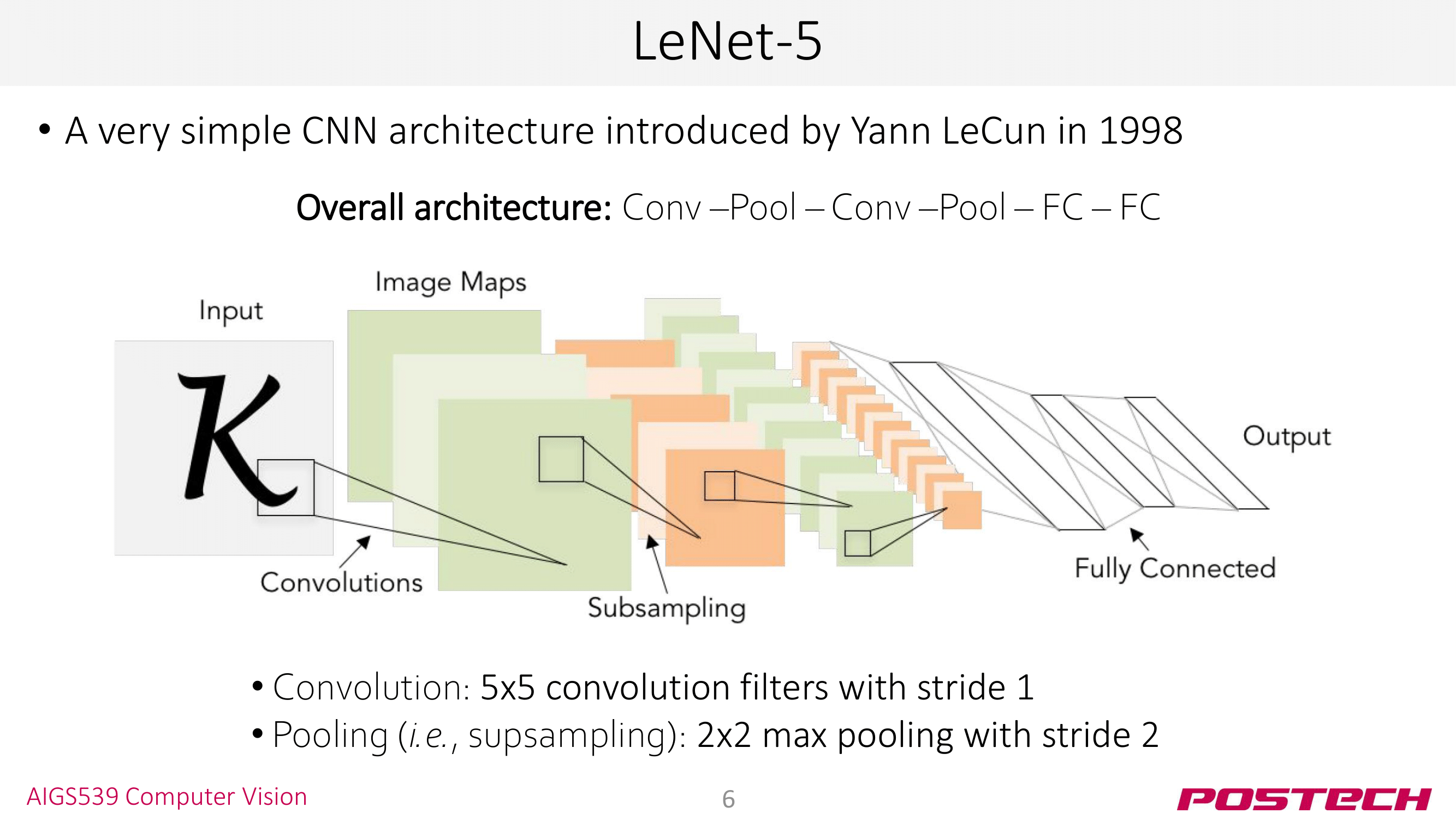
저번 seminr3에서 MNIST classification을 수행하는 LeNet을 구현했다. LeNet의 구조를 간단하게 아래와 같이 표현할 수도 있다.
(Conv - Pool) x 2 + FC x 2
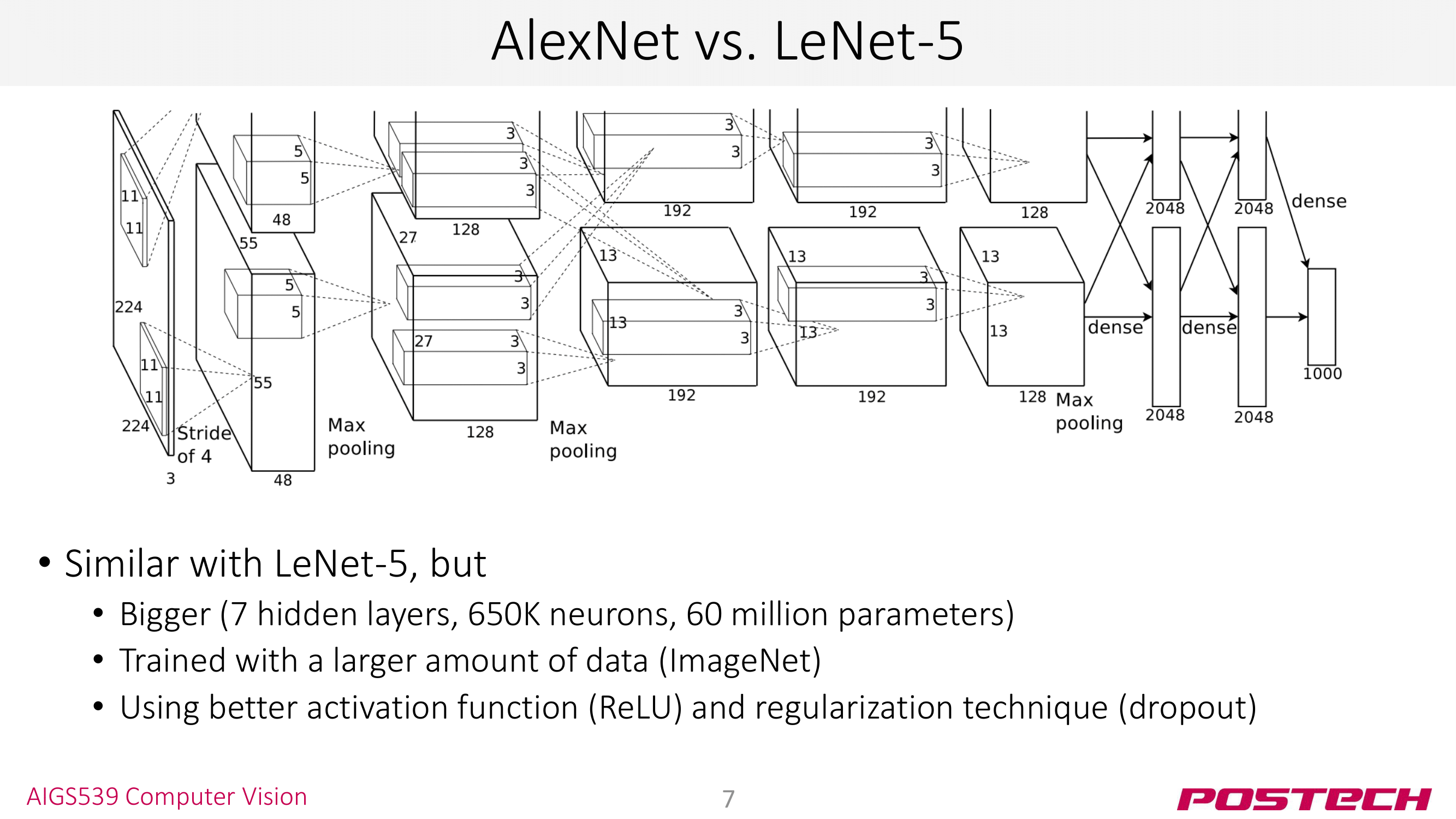
AlexNet은 ImageNet classification을 수행하는 CNN 모델이다. LeNet과 비교해보면 (1) 4 → 8 layer로 모델이 깊어지고 (2) MNIST보다 더 크고 많은 데이터를 가진 ImageNet 데이터셋으로 학습하고 (3) ReLU와 dropout 등의 테크닉을 도입한 모델이다.
LeNet과 모델 구조가 비교해 독특하다. 모델 구조를 보면 윗 부분과 아랫 부분이 있는데 2개의 모델을 따로 학습한 후 inference 단계에서 합쳐주는 ensemble(앙상블) 기법을 사용했다. VGG, ResNet은 앙상블 기법을 사용하진 않지만, 앙상블 기법 자체는 ML과 DL 분야 전반에서 널리 사용하는 테크닉이다.
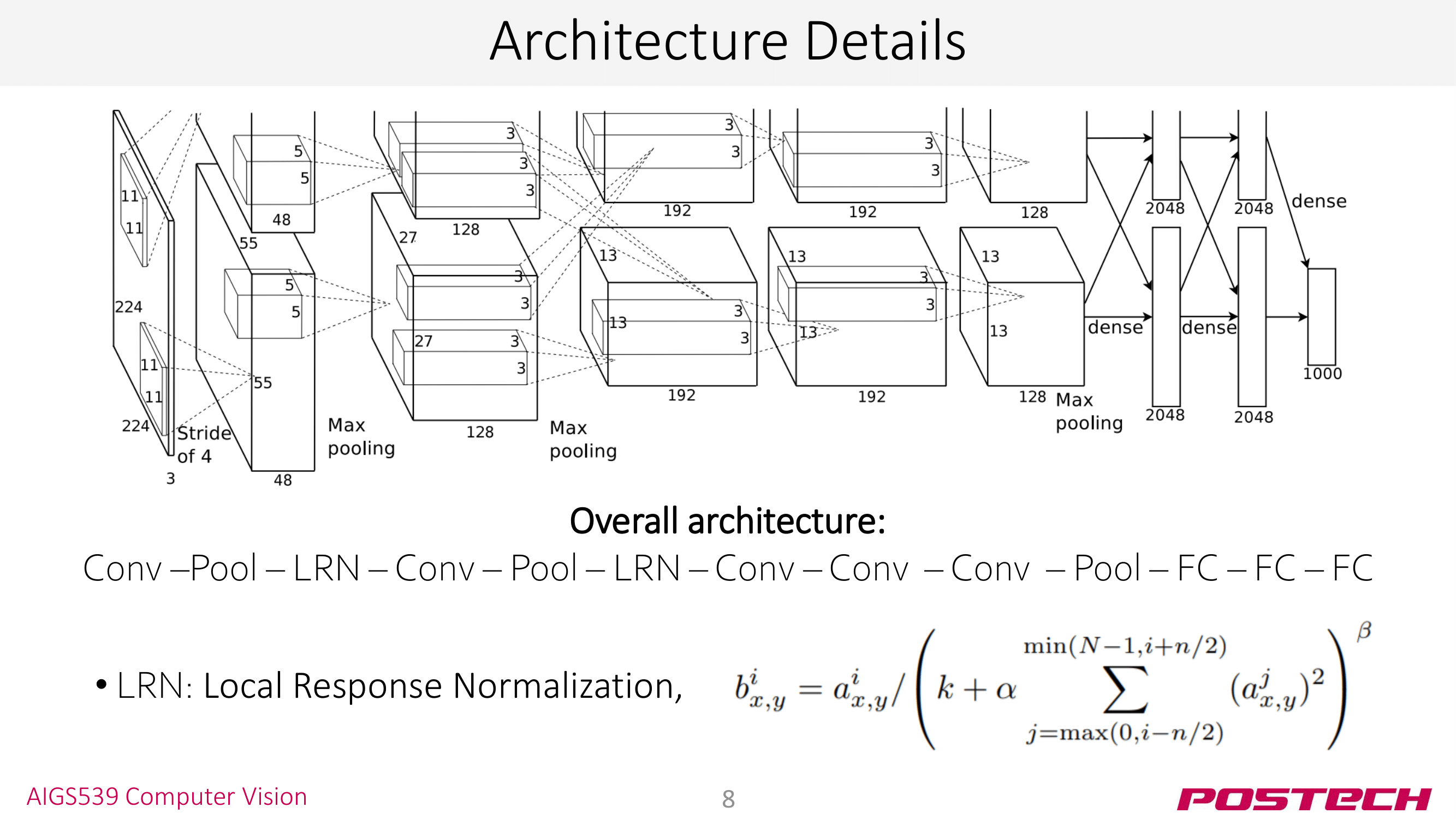
모델 구조를 좀더 살펴보자. AlexNet은 LRN이라는 테크닉이 사용해 conv layer의 출력을 정규화한다. LRN 식에서 $i$는 channel index인데, channel-wise normalization을 수행한다고 보면 된다. 요즘엔 LRN 성능이 그리 좋지 못하다고 알려져서 사용하지 않는다. 사진에는 LRN에 대한 수식이 있지만 굳이 이해하지 않고 넘어가도 된다.
VGGNet
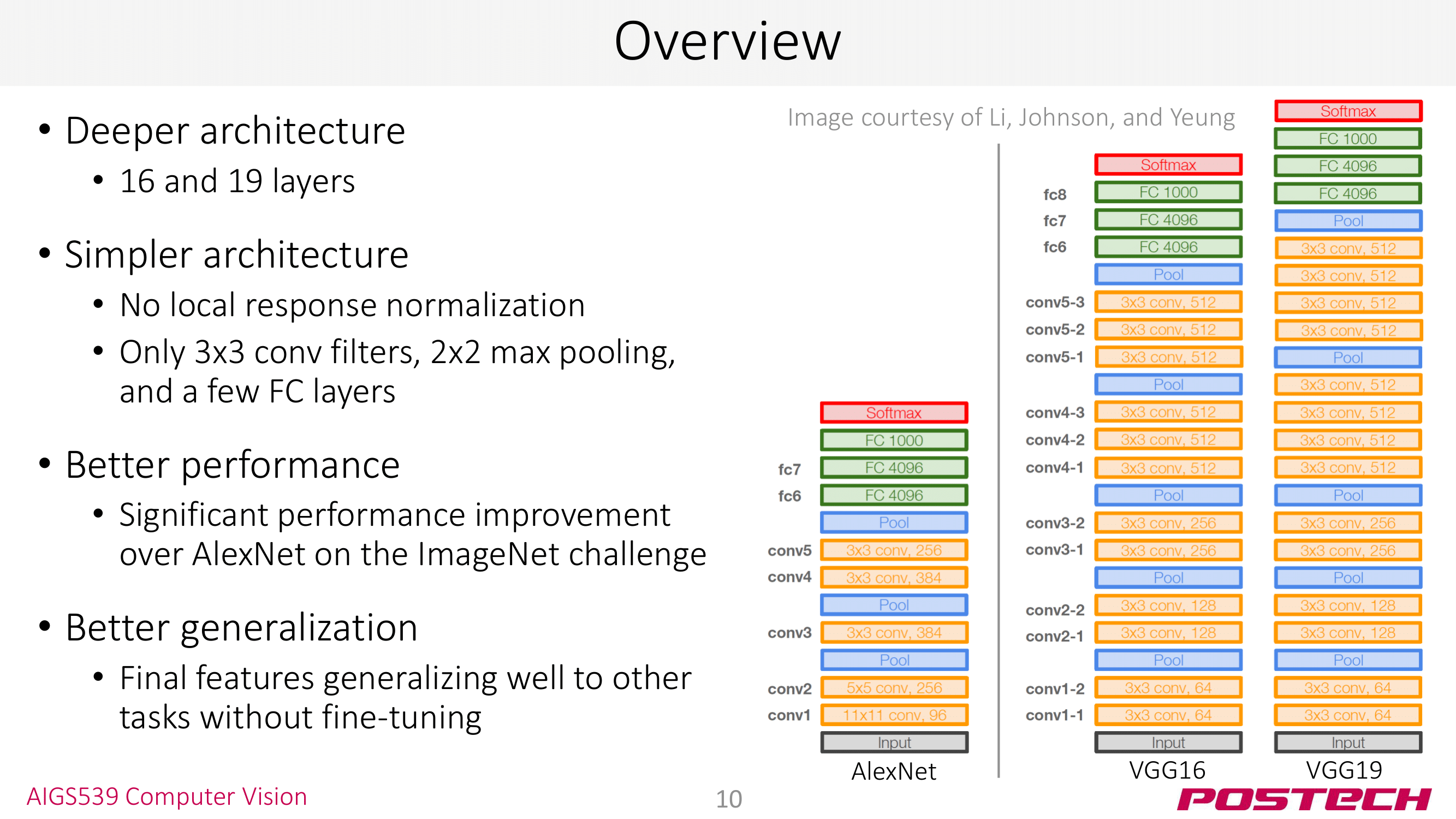
VGG 역시 ImageNet Classification 우승 모델이다. AlexNet과 비교해 (1) 더 깊은 구조 (8 → 16, 19) (2) 간단한 구조: LRN 사용 X, 3x3 conv 2x2 max pool만 사용했다는 특징이 있다.
VGG는 기존 AlexNet과 비교해 error rate을 16.4% → 7.3%까지 떨어뜨렸다. 게다가 VGG를 backbone 모델로 사용해 Classification 외에도 Detection, Segmenation 등의 태스크를 수행할 수 있다! (CNN architecture는 백본으로 사용된다!)
사진을 보면 VGG16, VGG19가 있는데 뒤에 붙는 숫자는 모델의 layer 수를 의미한다. 다른 모델도 이런 식으로 숫자를 붙여 layer 수를 표현한다 👏
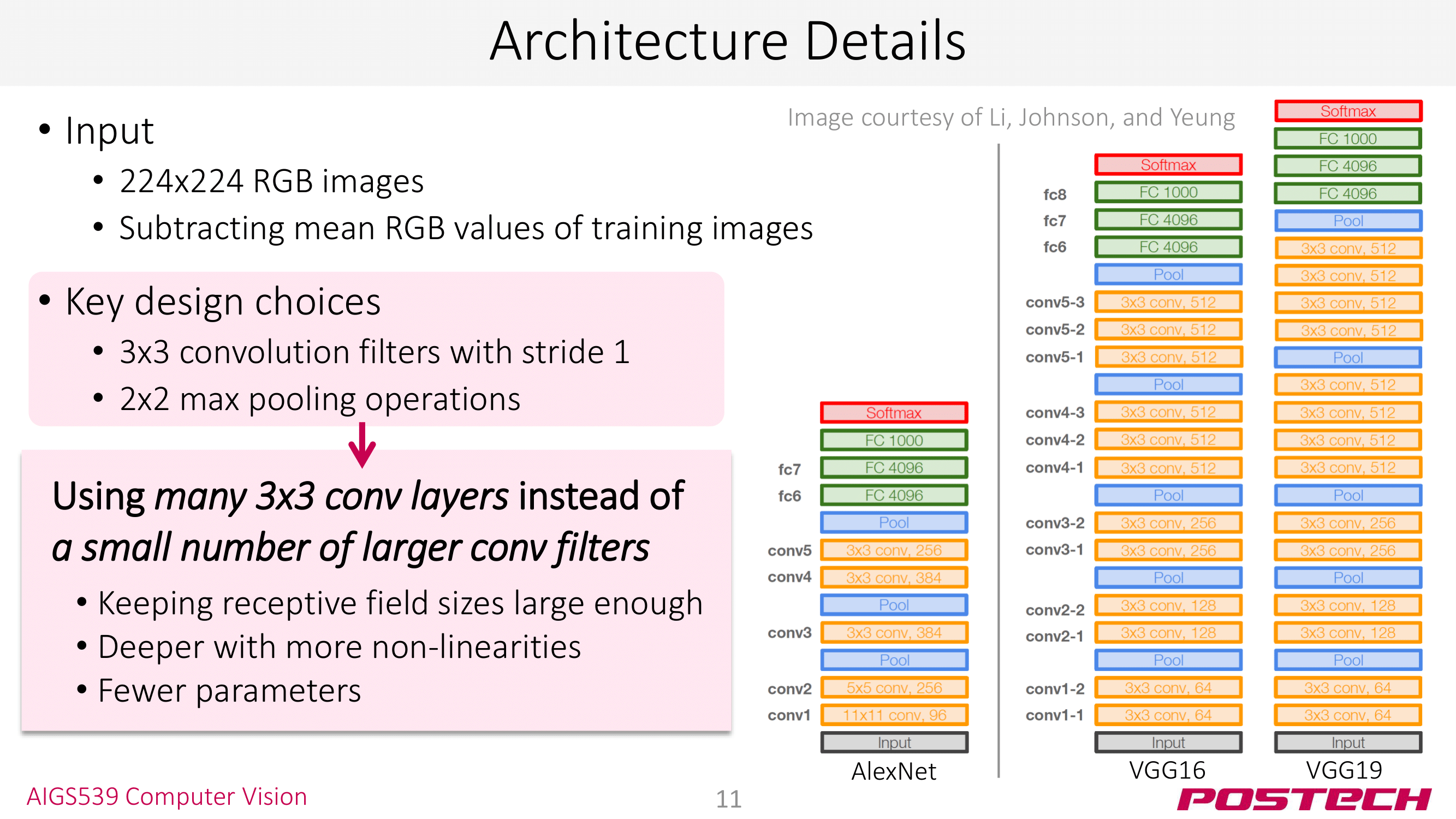
VGG에서 주목할 점은 3x3 conv, 2x2 max pool만을 사용했다는 것이다. 이전의 LeNet은 5x5 conv를 사용했다는 것과 비교하면 작은 사이즈의 kernel만을 사용한 것이다. 이런 3x3 conv 조합의 장점은 이미지(또는 feature map)이 conv layer를 지나도 크기가 거의 줄지 않는다는 것이다. 이렇게 되면 conv layer를 지나는 과정에서 손실이 적기 때문에 layer를 깊게 쌓는 것이 가능하다. 뒤에 나올 ResNet도 이 기법을 사용해 layer를 152까지 쌓을 수 있었다.
ResNet
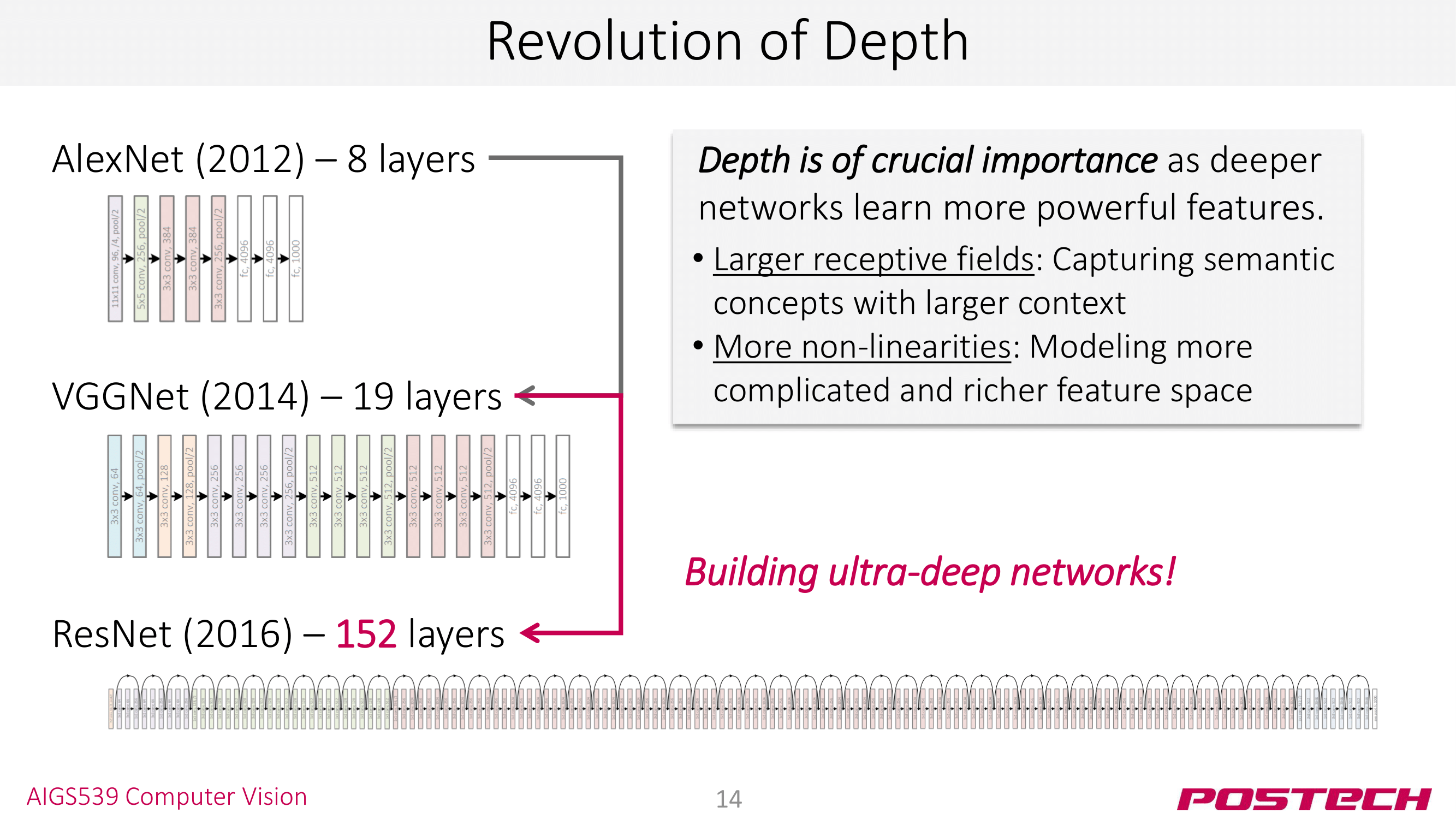
AlexNet과 VGGNet의 등장은 CNN architecture를 deep하게 쌓는 것이 꽤 괜찮은 접근임을 테크닉임을 제시했다. 그런데 AlexNet(8) → VGGNet(19)로 늘어나던 레이어 수가 ResNet에 와서는 152개로 한번에 뛰었다!! ResNet부터 ultra-deep network 우리가 말하는 딥러닝이 시작된 것이다 👏
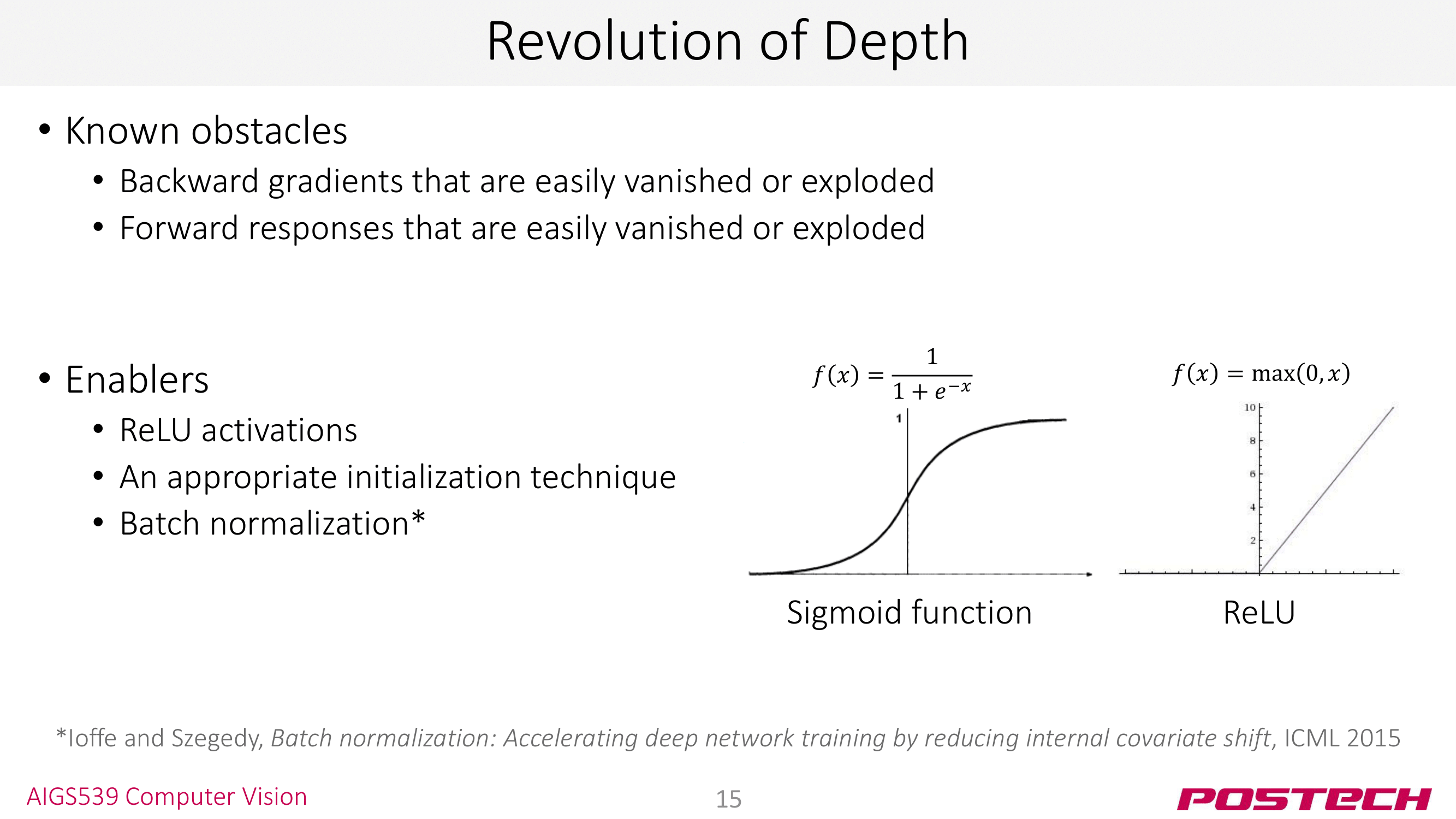
그러나 모델의 깊이를 마냥 늘리는 것은 Gradient Vanishing/Exploding 등의 문제를 야기한다. 그래서 ResNet은 이를 해결하기 위해 많은 테크닉을 사용한다. 우리가 흔히 아는 ReLU도 이런 deep architecture에서 발생하는 문제를 해결하기 위한 테크닉 중 하나다. 하나씩 살펴보자!
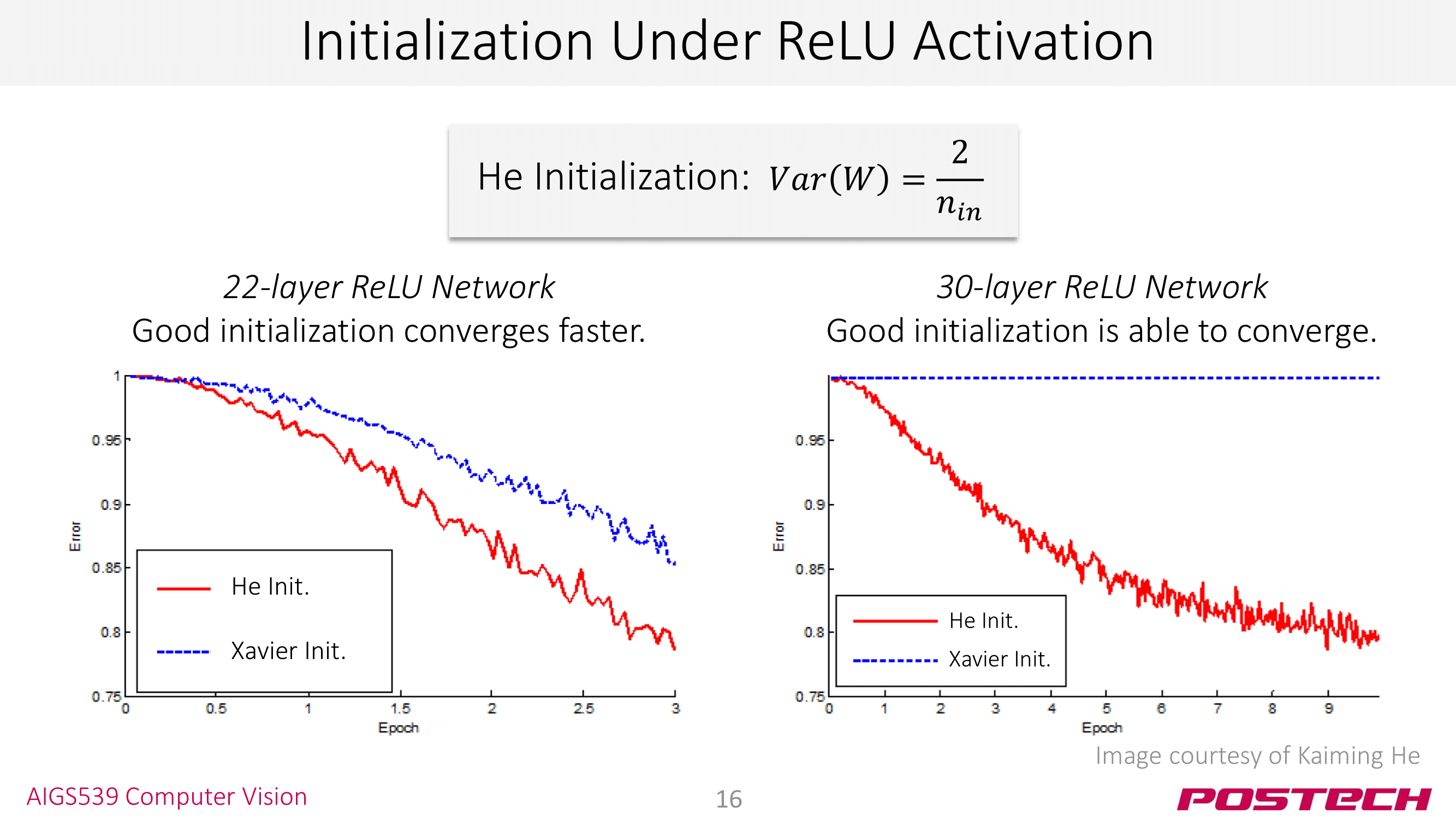
첫번째는 Weight Initialization이다. HW3의 숙제로 이미 공부하고 왔을 거라 생각한다. 👏 좋은 Weight Initialization이 더 빠른 converge와 더 향상된 퍼포먼스를 놓는다고 한다. Xavier Initialziation의 개선된 버전인 He Initialization이 ResNet의 저자 Kaiming He가 제시한 사실을 알면, ResNet이 deep CNN을 위해 많이 고민한 끝에 나온 모델임을 알 수 있을 것이다.
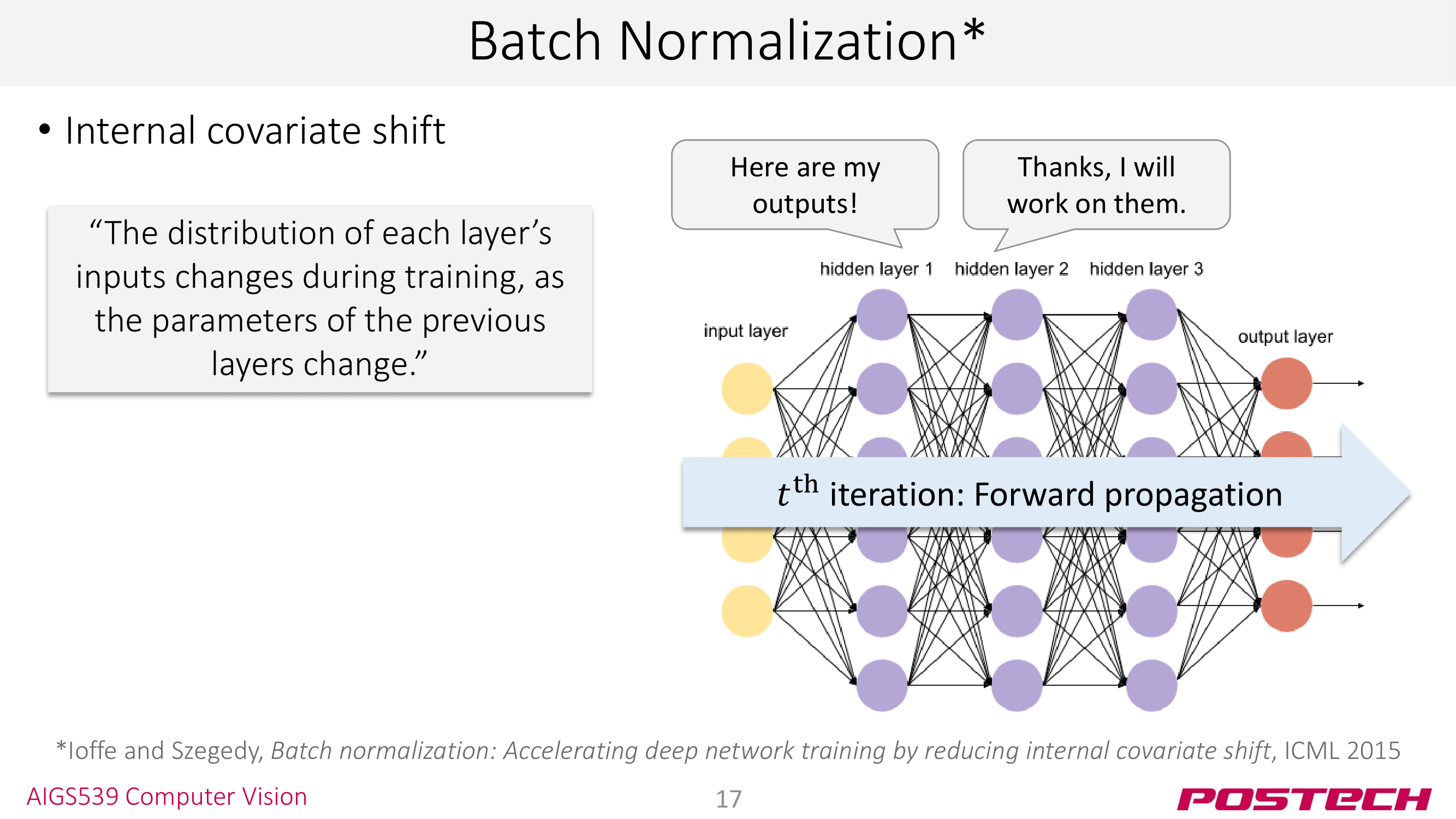
다음은 Batch Normalization이다. BN은 <internal covariate shift>라는 문제를 해결하기 위해 도입한 테크닉이다. 이것이 뭔지는 아래의 포스트를 참조해 설명하도록 하겠다.
1. covariate (공변량)
본인은 covariate와 covariance(공분산)을 헷갈렸어서 아래의 비교글을 참조하겠다.
“Covariance” is the raw version of correlation. It is a measure of the linear relationship between two variables. For instance, you could measure brain size and body weight (both in grams) across species. Then you could get the covariance but you would usually want to scale it and get the correlation.
“Covariate” is a variable in a regression or similar model. For instance, if you were modeling number of animals in a given area, you might have covariates such as temperature, season, latitude, altitude, time of day and so on.
즉, 모델링을 할 떄 종속 변수와 독립 변수 외의 다른 요인을 covariate로 취급한다. 또는 잠재 변수(latent variable)이라고 생각해도 좋을 것 같다.
2. covariate shift
간단하게 말해서 training set과 test set이 다른 분포를 가지는 경우를 말한다. 사실 trianing set과 test set을 단순한 테크닉으로 나눴다면 이런 현상을 마주할 가능성이 크다. 또, 모델을 학습 했을 때와 모델을 실제 서비스로 serving 할 때 입력되는 데이터는 늘 Gap이 있을 수 밖에 없다.
얼굴 인식 알고리즘은 대게 나이 먹은 얼굴보다는 젊은 얼굴로 학습을 시킨다.
3. internal covariate shift
이것은 모델 학습을 하는 과정에서 ‘학습을 하기 전’과 ‘학습을 하고 난 후’의 입력되는 값의 분포가 크게 달라지는 현상을 말한다.
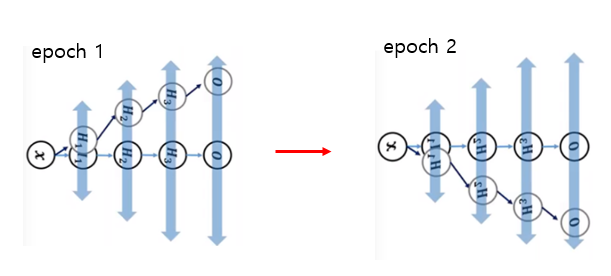
예를 들어, 첫 epoch에서는 첫번째 레이어의 결과가 양의 값을 가졌다. 그런데 첫 epoch을 돌고 parameter를 업데이트 한 후에는 첫번째 레이어가 음의 값을 뱉어버리는 것이다. 이렇게 되면 다음 두번째 레이어는 기존에 일력 받던 값보다 많이 변한 값을 입력 받게 되고, 그게 세번째 레이어로… 가면서 결국 이런 shifting이 누적되어 모델 학습 자체를 불안정하게 만든다. 이 문제는 레이어가 깊을수록 더 크게 나타날 것이다.

<Batch Normalization>은 이런 covariate shift를 완화하기 위해 레이어 사이에 normalization 레이어를 둔다. 그러면 아래와 같이 shifting 효과를 완화하여 다음 레이어로 전달되는 covariate shifting이 줄어들게 된다.

보통 학습을 할 때 mini-batch 단위로 하기 때문에 mini-batch 마다 normalization을 수행한다. mini-batch에 대해 mean $\mu_B$, variance $\sigma_B$를 구한 후 normalization을 한다.

마지막의 scale & shift 단계에서 $\gamma$와 $\beta$가 나오는데 둘 모두 trainalbe parameter로 학습 과정에서 자동으로 튜닝된다. CNN의 weight/bias 같은 BN의 parameter라고 생각하면 된다.
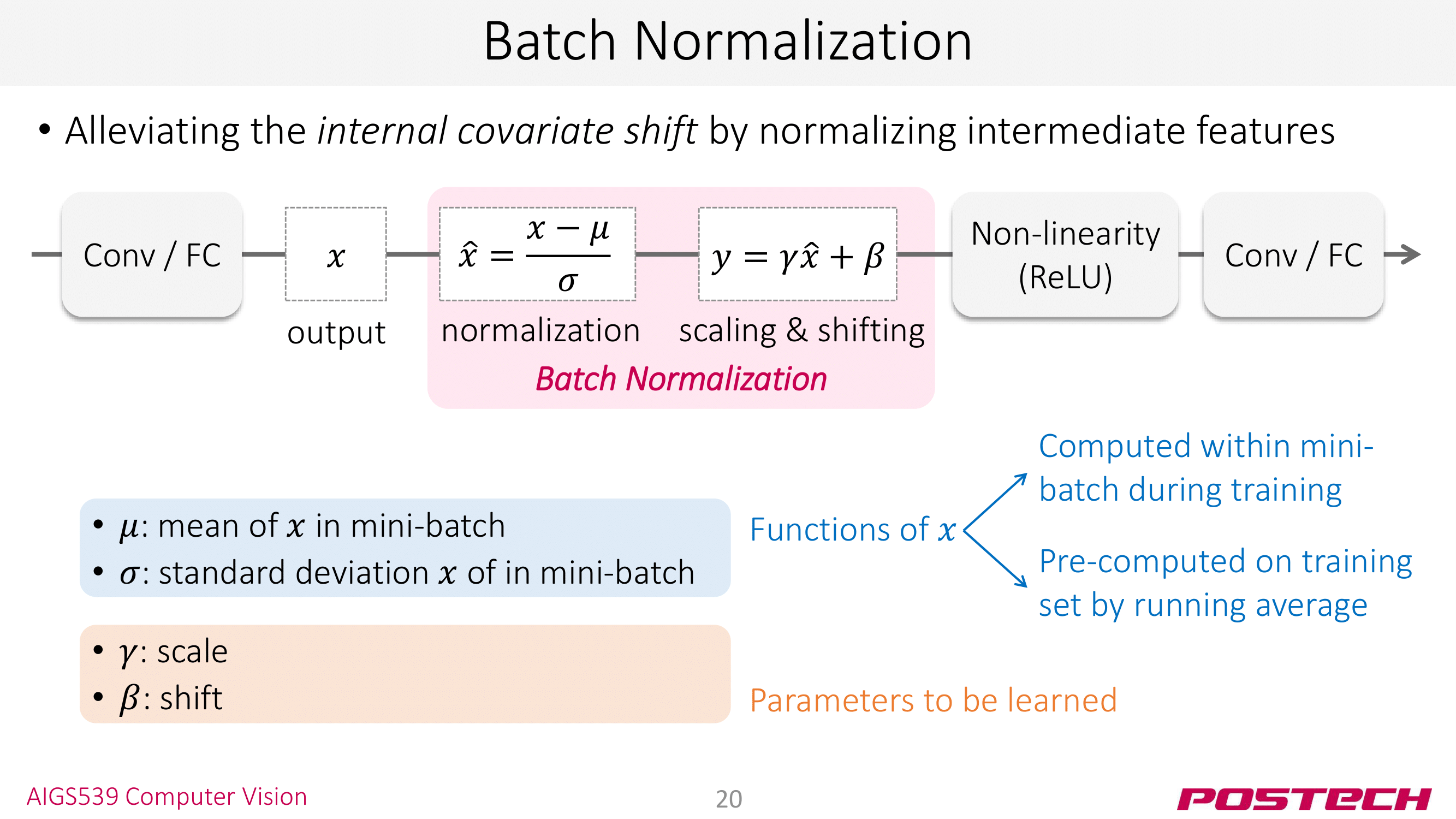

그러나 안타깝게도 network initialization과 batch normalization만으로는 ResNet처럼 152개나 되는 레이어를 쌓는 것은 불가능했다. 이것을 <degrdation problem>이라고 한다.
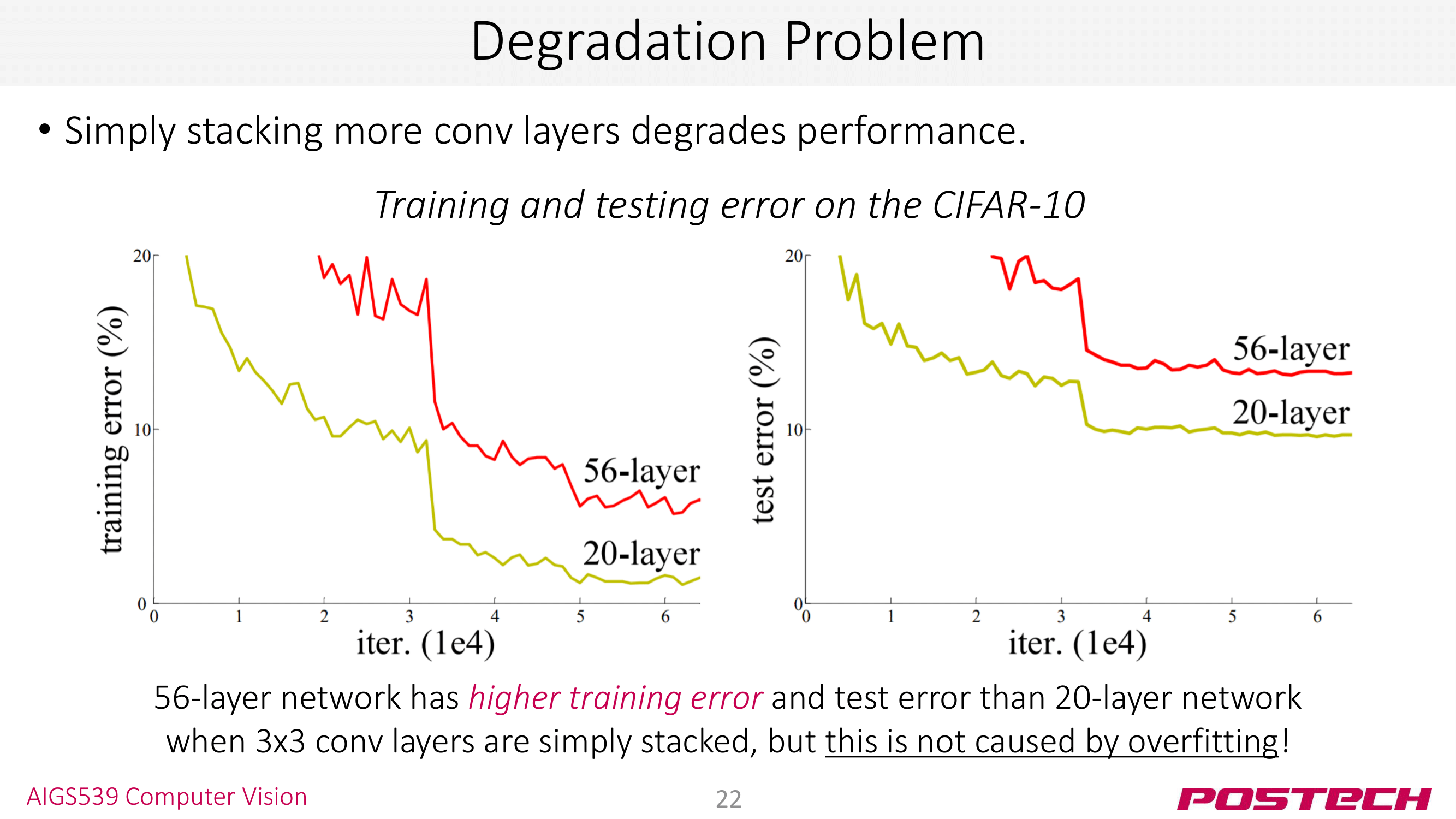
AlexNet과 VGGNet에서의 교훈은 “깊은 모델일수록 좋다”였다. 그러나 깊은 모델이 모든 것을 해결해주는 것은 아니었다. layer을 어느 정도 쌓게 되면 layer을 쌓을수록 error가 높아지는 문제가 발생한다. 이것이 <degradation problem>이라고 한다. (ps. gradient vanishing과는 다른 문제다!)
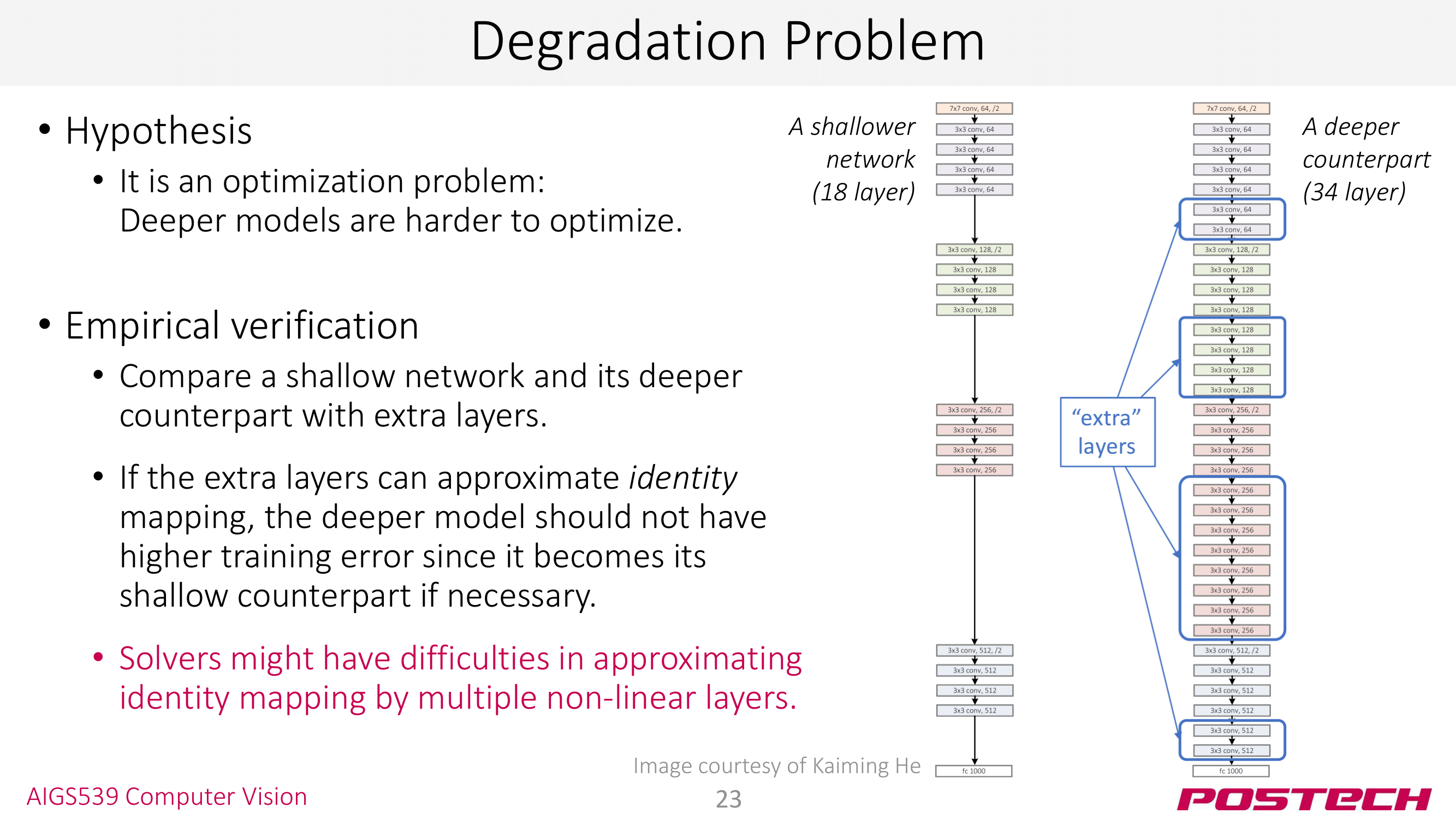
ResNet의 저자들은 <degradation problem>이 overfitting이 아니라 optimization 문제라고 판단했다. (보통 overfitting 문제라면 적절한 lr와 early termination으로 해결한다.) 그들은 18 layer의 얕은 모델과 얕은 모델 사이사이에 추가적인 layer를 끼운 깊은 모델 2개를 준비해 둘을 비교했다.
이때, 만약 extra layer가 identitiy mapping을 학습할 수 있어서 얕은 18 layer 모델과 깊은 34 layer 모델이 (거의) 동일해질 수 있다면, 모델이 깊다고 해서 높은 error를 가지진 않을 것이다.
그러나 실험 결과는 extra layer가 identitiy mapping을 학습하는 것이 불가능하다는 말한다. 이것은 hidden layer를 사용하면서 발생하는 non-linearity 때문이다.
이런 실험적인 이유 때문에 ResNet의 저자들은 layer가 identitiy mapping을 학습할 수 있도록 우회하는 residual network를 제시한다 👏

residual net의 아이디어 자체는 간단하다. 입력은 출력단에 더해주기만 하면 된다! 그러나 이런 단순한 테크닉이 정말로 identitiy mapping을 학습하기 쉽도록 만드는 것일까? 슬라이드의 내용은 이것이 가능하다는 것을 설명(explain)하고 있다.
자! 일단 identitiy mapping이 optimal이라고 하자. 그러면 모델은 아무것도 학습하지 않도록 해야 한다. 이것은 모델 paramter를 0 또는 0에 가깝도록 모델이 알아서 학습할 것이다.
그러나 만약 identitiy mapping이 optimal이 아니라 $x \rightarrow H(x)$가 optimal이더라도 걱정하지 않아도 된다. 그것은 residual net에서는 모델이 알아서 $x \rightarrow H(x) - x$를 학습하기 때문이다. 그래서 마지막에 $x$를 더해주면 결국 residual net을 쓰지 않아도 얻는 optimal mapping $x \rightarrow H(x)$를 얻게 되는 것이다! $\blacksquare$

ResNet의 기본 아키텍쳐 디자인인데, VGGNet의 컨셉인 3x3 conv만 사용만 확인하고 넘어가도 된다. 자세한 내용은 다음 세미나에서 ResNet을 직접 구현하면서 찬찬히 살펴볼 예정이다 👏
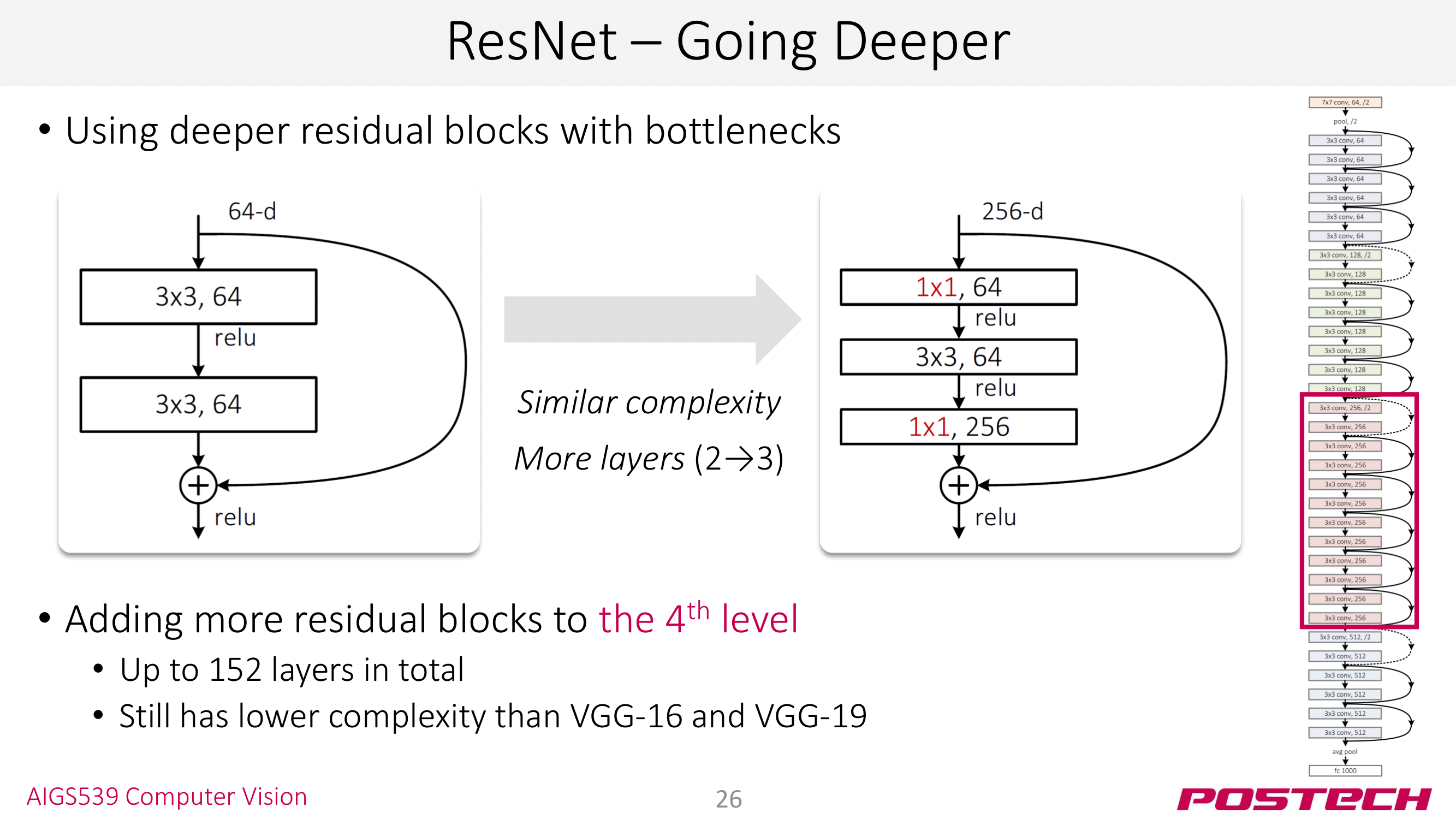
이 정도면 충분한 것 같은데… ResNet에서는 <bottleneck layer>라는 테크닉도 사용한다. 위의 슬라이드를 기준으로 말하면 입력 채널 256를 갑자기 64 채널로 줄여서 병목을 만드는 기법이다. 이때, 1x1 layer를 쓰기 때문에 convolution 연산은 되지만 이미지 크기는 그대로 유지된다. 그렇게 줄어든 채널에서 한번 더 conv 연산을 하고 다시 1x1 layer를 사용해 원본 채널인 256로 복구하는 기법이다.
이 기법을 왜 쓸까… 싶지만 이 <bottleneck layer>를 사용하면 layer 수를 늘리면서도 complexity는 동일하게 유지할 수 있다. 슬라이드를 기준으로 왼쪽의 2 layer와 오른쪽의 3 layer인 bottleneck layer는 동일한 complexity를 갖는다. 👏

이런 많은 노력과 테크닉을 사용해 ResNet은 모델의 깊이를 깊게 가져가면서도 높은 퍼포먼스를 얻을 수 있게 된다. 😎
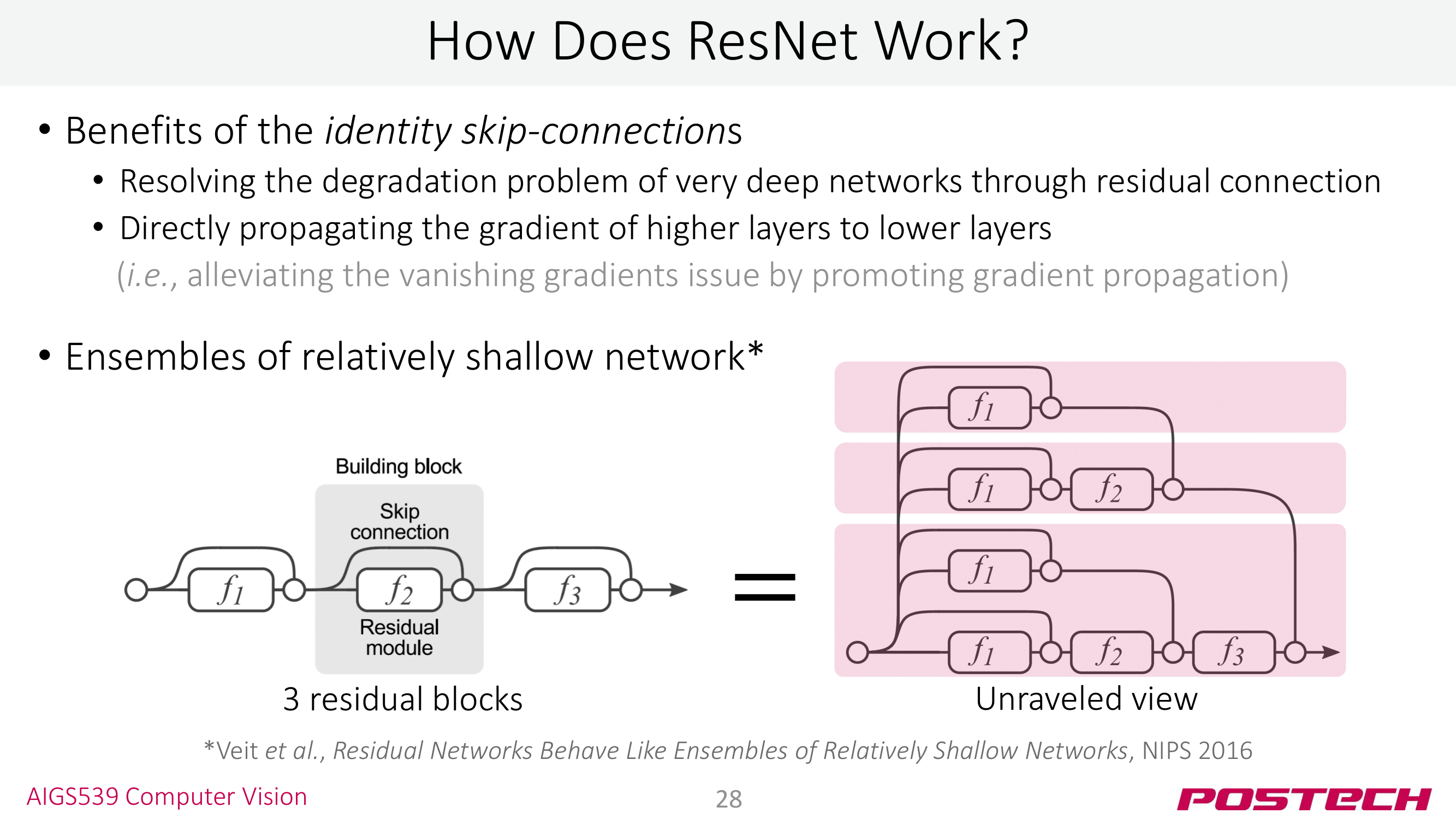
ResNet이 제시된 이후로 ‘왜 ResNet이 성공했을까…‘를 분석하는 연구들도 진행되었다. 간단하게 훑고 넘어가면
(1) skip-connection을 쓰면 higher layer의 gradient를 손실 없이 lower layer로 전달할 수 있다. (robust to gradient vanishing)
(2) residual layer를 쓰는 것은 ensemble layer의 형태로 학습하는 것과 유사한 효과를 얻는다.
ResNet을 이론적으로 설명하는 부분이라 사실 중요한 부분이긴 한데 컴퓨터 비전을 빡세게 할게 아니라면 ‘아 그렇구나’하고 넘어가도 된다 🙌
맺음말
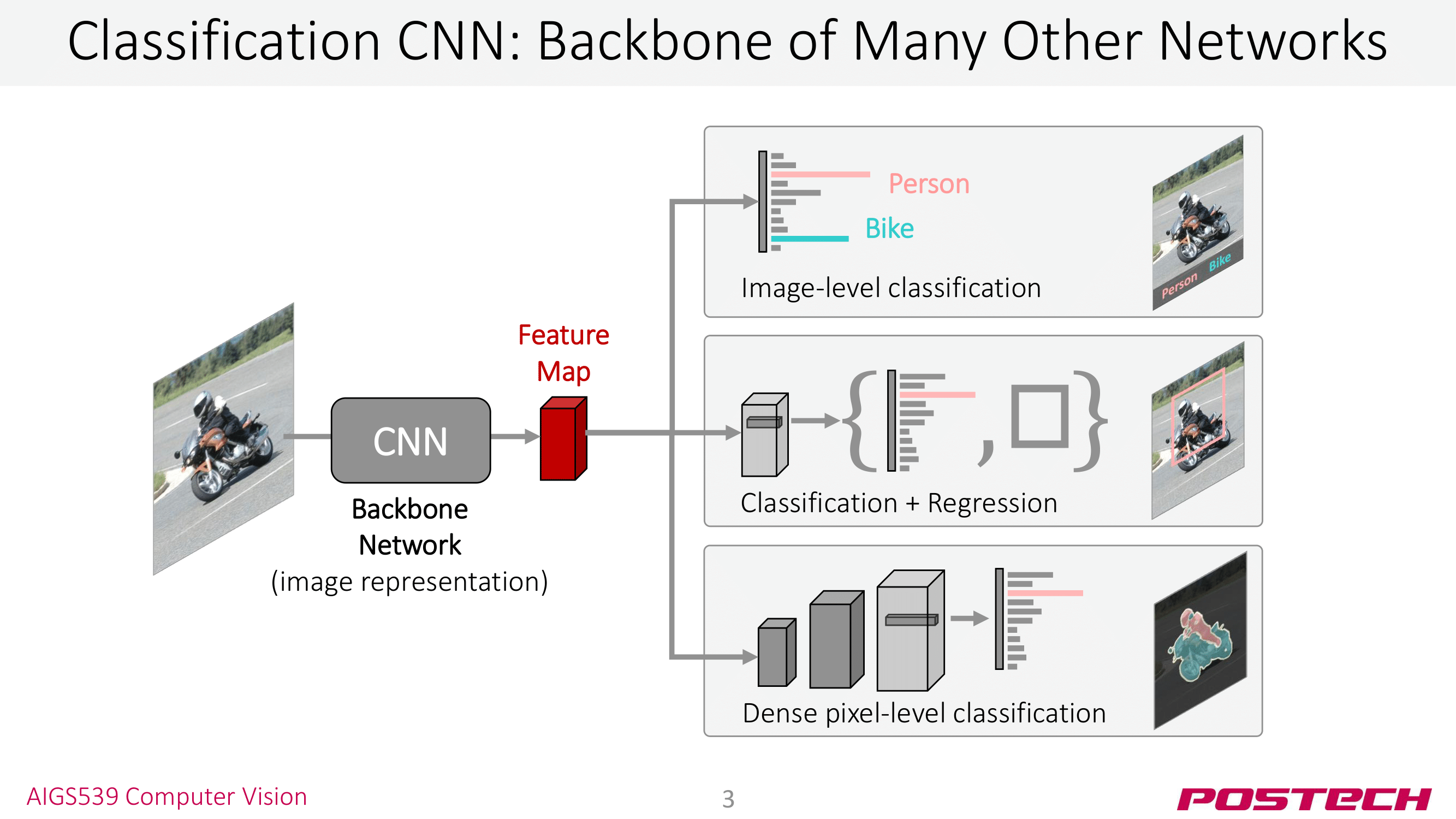
이번 세미나에서는 CNN Architecture에 대해 살펴봤다. 지금까지 소개한 CNN Architecture들은 모두 ImageNet Classification에서 사용된 모델들이라 ‘이걸 왜 공부할까…’, ‘난 Detection이나 GAN 같은게 더 재밌는데…’ 생각이 들지도 모른다. 그런데 이 CNN Architecture는 컴퓨터 비전의 다른 태스크 Image Detection, Image Segmentation 등등에 백본 네트워크로 사용된다 👏 그래서 이 부분을 잘 알아둬야 논문들을 읽을 때 쉽게쉽게 이해할 수 있다.
ResNet에 대한 내용은 대학원 면접 문제로도 출제된 적이 있다고 한다. 그만큼 중요한 모델이기 때문에 잘 이해하길 바란다. 다음 세미나에서는 이 ResNet을 pytorch로 직접 구현해보겠다 👨💻
reference
- POSTECH, CSED539: Computer Vision, 곽수하 교수님
- Batch Normalization