Seminar 3: MNIST CNN
이번 세미나부터 “컴퓨터 비전” 분야에 대한 주제를 시작합니다. 첫번째 주제는 Classification 입니다.
키워드
- CNN
- Image Convolutions
- Classification Model Implementation: MNIST
CNN
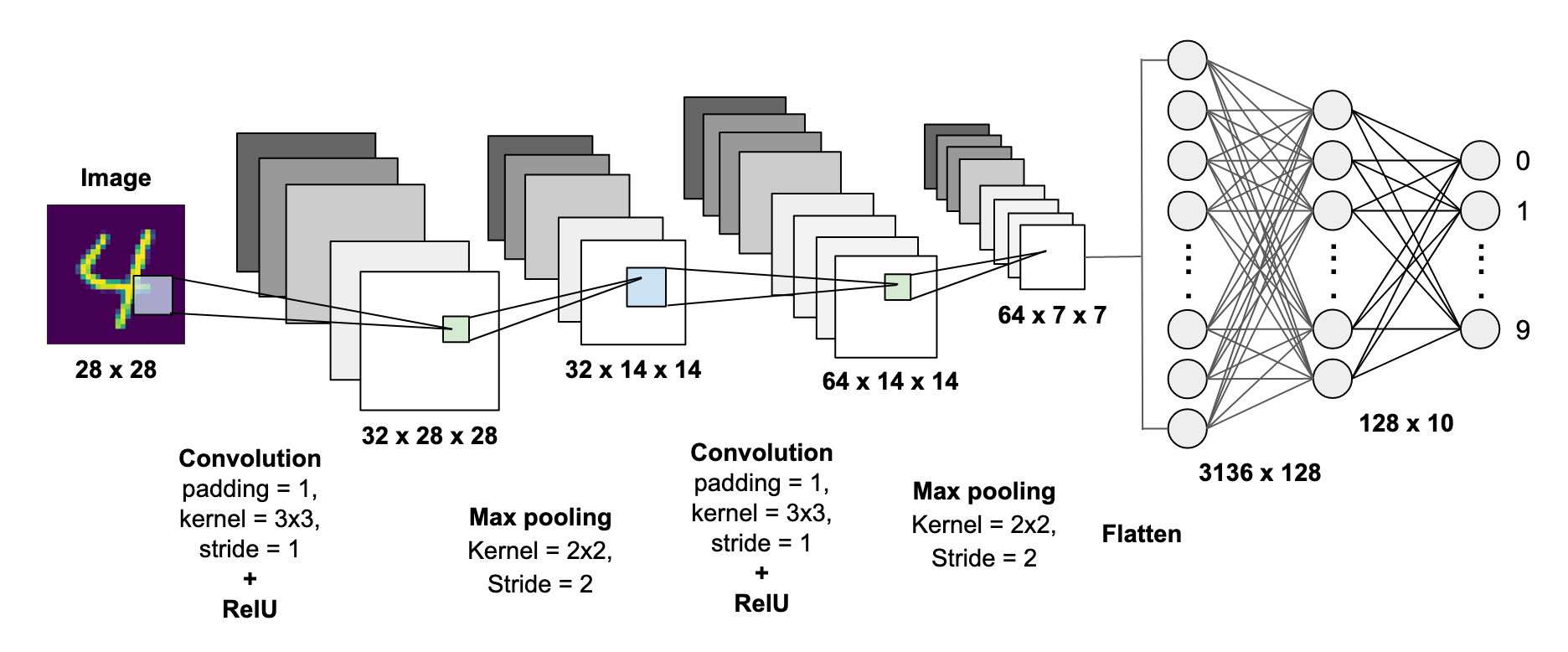
<CNN; Convolution Neural Network>는 이미지 데이터를 처리하는데 특화된 딥러닝 모델이다. CNN의 첫 부분은 Convoluyion Layer의 연속으로 이루어져 있다. 이 Convolution Layer는 “kerenl”이라는 정사각의 윈도우와 이미지를 Conv. 연산하여 이미지의 특징을 추출한다.
CNN 모델을 살펴보기 전에 이 Image Convoluyion과 kernel이라는 녀석에 대해 좀더 살펴보고 가자. 사실 이미지에 대한 Convolution 연산은 CNN이 제시되기 이전부터 컴퓨터 비전 분야에서 존재했던 개념이다. 대표적인 Image Convolution 두 가지를 살펴보고 가자.
Image Convolutions
1. Gaussian Filter
\[\frac{1}{16} \begin{bmatrix} 1 & 2 & 1 \\ 2 & 4 & 2 \\ 1 & 2 & 1 \end{bmatrix}\]가장가리로 갈수록 값이 줄어드는 Gaussian Filter는 2D 가우시안을 3x3의 행렬에 Discrete 하게 표현한 것이다.
이 녀석을 이미지에 적용하면

흔히 이미지를 블러 처리하기 위해 Gaussian Filter를 사용한다. 이런 블러 처리는 이미지에 포함된 noise의 효과를 옅어지게 만들어 noise robust한 분석을 하기 위해 주로 사용한다. 자세한 내용은 컴퓨터비전(CSED539) 과목에서 배울 수 있다 👏
2. Sobel Filter
\[\begin{bmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{bmatrix}\]가운데가 0이고, 한쪽이 음수, 다른쪽이 양수인 Sobel Filter는 이미지의 Edge를 검출하는 필터다.
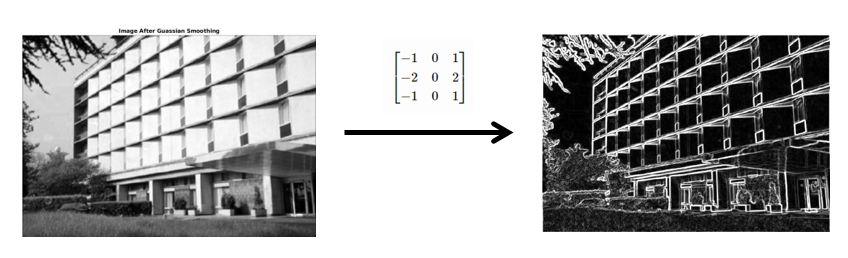
보통은 이미지에 Gaussian Filter로 Gaussian smoothing 한 후에 Sobel Filter로 Edge Detection을 수행한다.
사실 우리가 배우는 딥러닝과는 그렇게 관련있는 내용은 아니었지만, Convolution Layer가 어떤 맥락에서 나왔는지를 설명하려고 컴퓨터 비전 초기의 이론을 잠깐 가져왔다. 위의 Image Convolution Filter들은 모두 이미지를 noise-robust하게 만들거나(Gaussian Filter), 이미지의 Edge를 추출하거나(Sobel Filter) 등의 역할을 해왔다. 즉, 이미지를 가공하거나 특징을 추출하는 도구로 사용되어 왔다는 것이다.
우리가 CNN에서 사용하는 Convolution Layer도 이 필터들과 크게 다르지 않다. 이미지를 쓰기 편하게 가공하거나 이미지의 특징을 추출한다. 다만, 컴퓨터 비전 초기와 딥러닝의 Convolution Layer가 다른 점은 Gaussian/Sobel Filter는 목적에 따라 정해진 값이 있는 필터라는 것이고, 딥러닝의 Convolution Layer는 우리가 별도로 값을 정해주지 않아도 딥러닝 학습에 의해 Convolution Filter의 값이 학습된다는 것이다. 👏
Let’s CNN
자! 이제 CNN 모델을 pytorch로 구현해보자. 여러분이 HW2를 잘 풀어왔다면👀 CNN의 Conv Layer, Pooling, Padding 등은 이미 알고 있을 것이다. 그러니 설명은 생략하고 바로 CNN 모델을 구현해보자!
먼저 PyTorch의 Conv. Layer인 nn.Conv2d()에 대해 살펴보자.
nn.Linear(in_features, out_features)
nn.Conv2d(in_features, out_features, kernel_size)
nn.Conv2d()도 nn.Linear()처럼 입력 피처 수와 출력 피처 수를 인자로 받는다. 다만, Conv2d()는 kernel 사이즈를 정해줘야 하므로 추가로 kernel_size가 필요하다.
nn.Conv2d(1, 1, 5) # 흑백 이미지를 흑백 이미지로
nn.Conv2d(3, 3, 5) # 컬러 이미지를 컬러 이미지로
nn.Conv2d(1, 6, 5) # 흑백 이미지를 6채널의 이미지로
자! 그럼 PyTorch nn.Conv2d()를 알았으니 CNN 모델을 만들어보자! 이번에는 PyTorch의 nn.Module을 상속받는 커스텀 모델을 만들어 볼 것이다.
import torch.nn as nn
class MyCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
위의 코드는 2개의 Conv layer로 구성된 딥러닝 모델을 구현한 것이다. PyTorch 커스텀 모델을 만들 때는 nn.Module을 상속 받는 클래스를 정의하면 된다. 이때, __init__()에는 사용할 nn layer들을 정의하고, forward()에는 모델에 들어오는 입력을 처리하는 로직을 구현한다.
계속 CNN 모델을 구현해보자. 2번의 Conv layer 사이에는 Pooling Layer를 붙여준다. PyTorch의 F.max_pool2d() 함수를 사용한다.
# add pooling layer
import torch.nn.functional as F
class MyCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
def forward(self, x):
x = self.conv1(x)
x = F.max_pool2d(x)
x = self.conv2(x)
x = F.max_pool2d(x)
return x
max_pool2d(tensor, kernel_size)은 weight/bias 같은 학습할 파라미터가 없기 때문에 __init__()에 정의하지 않고 forward()에 바로 정의해서 쓰면 된다.
다음은 Conv layer 다음의 FC layer를 구현하자. seminar2에서 배운 nn.Linear()를 쓰면 된다.
class MyCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.conv1(x)
x = F.max_pool2d(x, 2)
x = self.conv2(x)
x = F.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
왜 fc1의 in_features가 16 * 4 * 4이고, fc3의 out_features가 10일까 싶을 것이다.

그 이유는 우리가 MNIST 데이터셋으로 0~9 숫자를 분류하는 CNN 모델을 만들 것이기 때문이다. MNIST 데이터를 conv2까지 처리하면 4 x 4 x 16의 텐서가 되고, 마지막에 0~9 카테고리에 대해 분류해야 하기 때문에 마지막 fc3의 out_features를 10으로 설정한다.
forward() 부분에서 FC layer에 넣기 전에 torch.flatten(x, 1)을 쓰는데, H x W x C로 된 텐서를 H * W * C로 납작하게 만드는 함수다.
이제 CNN의 큰틀은 완성한 상태다. 남은 것은 ReLU layer다. 각 layer의 출력에 F.relu()로 ReLU function을 넣주자.
class MyCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
좌자잔! 여러분은 첫 CNN 모델을 구현한 것이다! 👏 모델이 잘 동작하는지 확인하려면 데이터가 필요하다. 우리는 MNIST 데이터셋을 사용할 것이다.
TorchVision: MNIST
PyTorch는 MNIST와 같이 유명한 데이터셋을 쉽게 쓸 수 있도록 라이브러리를 제공한다. 비전 쪽 데이터는 torchvision.datasets에서 쉽게 사용할 수 있다. torchvision.datasets
우리는 torchvision에서 제공하는 MNIST 데이터셋을 사용할 것이다. torchvision.dataset.MNIST 명세를 잘 읽어보면 root, train, download, transform 등의 인자가 있다. 일단은 아래의 코드를 실행해 데이터를 얻자.
import torchvision
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True)
print(len(trainset))
print(len(testset))
그러면 ./data 폴더에 MNIST 데이터셋이 저장된다. 그리고 별도로 Custom Dataset을 정의할 필요없이 torchvision에서 제공하는 MNIST 데이터셋을 사용하면 된다! 👏
MNIST 데이터가 잘 받아졌는지 확인해보자.
image, label = trainset[0]
print(image, label)
display(image)
DataLoader도 정의하자.
from torch.utils.data import DataLoader
batch_size = 4
train_dl = DataLoader(trainset, batch_size=batch_size, shuffle=True)
test_dl = DataLoader(testset, batch_size=batch_size, shuffle=False)
Train CNN Model!
자! 이제 데이터셋도 준비되었으니 CNN 모델을 학습시켜보자! 👏 그런데 본격적인 학습 플로우를 만들기 전에 모델과 데이터셋이 잘 붙는지 디버깅을 먼저 해야 한다. 디버깅 꼭 해야 한다…
# 디버깅 먼저!
image, label = trainset[0]
myCNN = MyCNN()
myCNN(image)
데이터셋을 바로 사용하게 되면 image 객체가 tensor가 아니기 때문에 오류를 뱉는다.
# 디버깅 먼저!
import numpy as np
image, label = trainset[0]
image = np.array(image)
image = torch.Tensor(image)
myCNN = MyCNN()
myCNN(image)
tensor로 바꿔줘도 오류가 날 텐데, (1) 흑백 이미지를 입력으로 넣을 것이니 1 x W x H의 이미지를 넣어야 한다 (2) 배치 차원 추가 B x 1 x W x H를 안 해줬기 때문이다.
# 디버깅 먼저!
import numpy as np
image, label = trainset[0]
image = np.array(image)
print(type(image), image.shape)
image = torch.Tensor([image])
print(type(image), image.shape)
image = image.unsqueeze(0)
print(type(image), image.shape)
myCNN = MyCNN()
myCNN(image)
출력 결과로 아래와 같이 10차원의 텐서를 뱉으면 모델이 잘 구축된 것이라고 볼 수 있다! 👏
tensor([[ 2.2457, -5.4209, -3.1778, 1.5650, -0.3050, 2.3941, -1.7845, -1.9811,
-3.0732, 3.0183]], grad_fn=<AddmmBackward0>)
torch.Size([1, 10])
그런데 잠깐! 방금의 디버그에서 우리는 trainset[0]의 이미지를 직접 Tensor로 바꾸고, 흑백 이미지를 표현하기 위해 1 x W x H로 변환도 했다. 사실 이 과정을 직접 하지 않고, trainset을 구축하는 과정에서 바로 할 수도 있는데… torchvision.transforms을 쓰면 된다! 👏
import torchvision.transforms as transforms
transform = transforms.ToTensor()
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
image, label = trainset[0]
print(type(image), image.shape)
print(label)
코드를 보면 MNIST 데이터셋에 transform 인자로 ToTensor()를 넣어줬다. 이를 통해 이미지에 변환하는 과정을 직접 수행하지 않고, 콜백 함수 형태로 넘길 수 있다!
사실 데이터셋 전처리, 여기서는 이미지 전처리 단계가 하나 더 남았는데 바로 Normalization이다. seminar2에서 Linear Regression을 구현할 때도 Normalization을 수행했는데 그걸 이미지 데이터에 대해서도 한다고 생각하면 된다. transform을 아래와 같이 수정하면 이미지를 Normalize 한다.
import torchvision.transforms as transforms
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(0, 1)])
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
image, label = trainset[0]
print(type(image), image.shape)
print(label)
보면 transforms.Compose()란 걸 썼는데 여러 개의 전처리 과정을 묶고 싶을 때 쓰는 녀석이다.
이제 정말로 디버그는 끝났다!! 원래 이렇게 신경 써줄게 많다 ㅠㅠ 위 과정에서 했던 transform을 기존의 trainset/testset과 dataloader에도 적용하고 모델을 만들어 보자!
디버그 끝! 진짜 모델 학습!
저번 seminr2의 마지막에 봤던 딥러닝 학습 플로우를 그대로 따라가면 된다.
# prepare dataset
data = df.read_csv(...)
# create custom dataset class
class MyDataset(Dataset):
...
# build DL model
model = nn.Linear(...)
# prepare dataloader
dl_train = DataLoader(...)
# prepare optimizer
optimizer = optim.SGD(...)
# Do SGD
for epoch in range(MAX_EPOCH):
# train phase
for X, y in dl_train:
y_pred = model(X)
loss = ...
# Back-prop
optimizer.zero_grad()
loss.backward()
optimizer.step()
# eval phase
evaluate(dl_train)
evaluate(dl_val)
evaluate(dl_test)
이번에는 분류 모델을 만들기 떄문에 Loss Function으로 nn.CrossEntropyLoss()를 사용한다. 분류 모델의 Loss에 대해선 이미 알고 있을 거라 생각하고 따로 설명하진 않겠다 👏
# prepare dataset
# 위에서 했음.
# build DL model
# 커스텀 모델 정의는 위에서 했음.
myCNN = MyCNN()
# prepare dataLoader
# 위에서 했음.
# prepare optimizer
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(myCNN.parameters(), lr=0.001, momentum=0.9)
# Train Model!
...
자 이제 모델 학습 부분의 코드를 짜면…
# Train Model!
MAX_EPOCH = 101
for epoch in range(MAX_EPOCH):
total_loss = 0
for X, y in train_dl:
optimizer.zero_grad()
y_pred = myCNN(X)
loss = criterion(y_pred, y)
total_loss += loss.item()
loss.backward()
optimizer.step()
print(f'[epoch {epoch}]: {total_loss / len(trainset):.4f}')
가 되는데, 실제로 학습 돌려보면 100 epoch을 도는데 시간이 꽤 걸린다… 그 이유는 batch_size와 GPU를 사용하지 않아서 인데 코드를 약간 수정하자.
1. batch_size 조정
batch_size = 64
train_dl = DataLoader(trainset, batch_size=batch_size, shuffle=True)
test_dl = DataLoader(testset, batch_size=batch_size, shuffle=False)
# Train Model!
MAX_EPOCH = 101
for epoch in range(MAX_EPOCH):
total_loss = 0
for X, y in train_dl:
optimizer.zero_grad()
y_pred = myCNN(X)
loss = criterion(y_pred, y)
total_loss += loss.item()
loss.backward()
optimizer.step()
print(f'[epoch {epoch}]: {total_loss / len(trainset):.4f}')
2. GPU로 모델 학습
myCNN = MyCNN()
myCNN = myCNN.cuda()
optimizer = optim.SGD(myCNN.parameters(), lr=0.001, momentum=0.9)
# Train Model!
MAX_EPOCH = 101
for epoch in range(MAX_EPOCH):
total_loss = 0
for X, y in train_dl:
optimizer.zero_grad()
X = X.cuda()
y = y.cuda()
y_pred = myCNN(X)
loss = criterion(y_pred, y)
total_loss += loss.item()
loss.backward()
optimizer.step()
print(f'[epoch {epoch}]: {total_loss / len(trainset):.4f}')
이 단계에서 적절한 batch_size는 Colab의 “런타임 -> 세션 관리” 탭의 GPU 사용량을 보고 GPU 오버가 나지 않을 정도로 해서 잘 조정하면 된다 😉
자! 그럼 이제 train/test 성능 측정까지 포함해 모델을 완성해보자. 이번에는 val set은 운용하지 않겠다 🙏
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.optim as optim
USE_CUDA = True
# prepare dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(0, 1)])
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
# build DL model
class MyCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
myCNN = MyCNN()
if USE_CUDA:
myCNN = myCNN.cuda()
# prepare dataLoader
BATCH_SIZE = 128
train_dl = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
test_dl = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False)
# prepare optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(myCNN.parameters(), lr=0.001, momentum=0.9)
# Train Model!
total_tic = time.time()
# Train Model!
MAX_EPOCH = 21
for epoch in range(MAX_EPOCH):
tic = time.time()
# train
total_train_loss = 0
total_train_correct = 0
for X, y in train_dl:
optimizer.zero_grad()
if USE_CUDA:
X = X.cuda()
y = y.cuda()
y_pred = myCNN(X)
value, index_pred = torch.max(y_pred.data, 1)
total_train_correct += (index_pred == y).sum().item()
loss = criterion(y_pred, y)
total_train_loss += loss.item()
loss.backward()
optimizer.step()
# test
total_test_loss = 0
total_test_correct = 0
with torch.no_grad():
for X, y in test_dl:
if USE_CUDA:
X = X.cuda()
y = y.cuda()
y_pred = myCNN(X)
value, index_pred = torch.max(y_pred.data, 1)
total_test_correct += (index_pred == y).sum().item()
loss = criterion(y_pred, y)
total_test_loss += loss.item()
toc = time.time()
print(f'===== {epoch} ====')
print(f'elaps: {toc - tic:.1f} sec')
print(f'[train] loss: {total_train_loss / len(trainset):.4f}, acc: {total_train_correct / len(trainset):.3f}')
print(f'[test] loss: {total_test_loss / len(testset):.4f}, acc: {total_test_correct / len(testset):.3f}')
total_toc = time.time()
print(f'[Total Run]: {total_toc - total_tic:.1f} sec')
boolean의 USE_CUDA를 추가해 손쉽게 CPU/GPU 스위칭 할 수 있도록 코드를 구성했다 🙏 본래는 Loss 그래프와 Acc 그래프까지 그려야 하지만 그 부분은 숙제로 남겨두겠다 😉
맺음말
오늘 우리가 구현한 모델은 LeNet(Yann LeCun, 1989) 모델로 최초로 CNN 구조를 사용해 문제를 해결한 모델이다. 오늘의 코드 역시 LeNet의 구조를 따라 작성되었다. LeNet 논문을 읽어볼 필요는 없다. 다만, HW에서 LeNet 이후의 CNN Architecture에 대한 내용들을 공부하는 것이 과제로 나갈 예정이다.
다음 세미나에서는 VGG, ResNet 등 CNN Architecture에 대해 살펴보도록 하겠다.